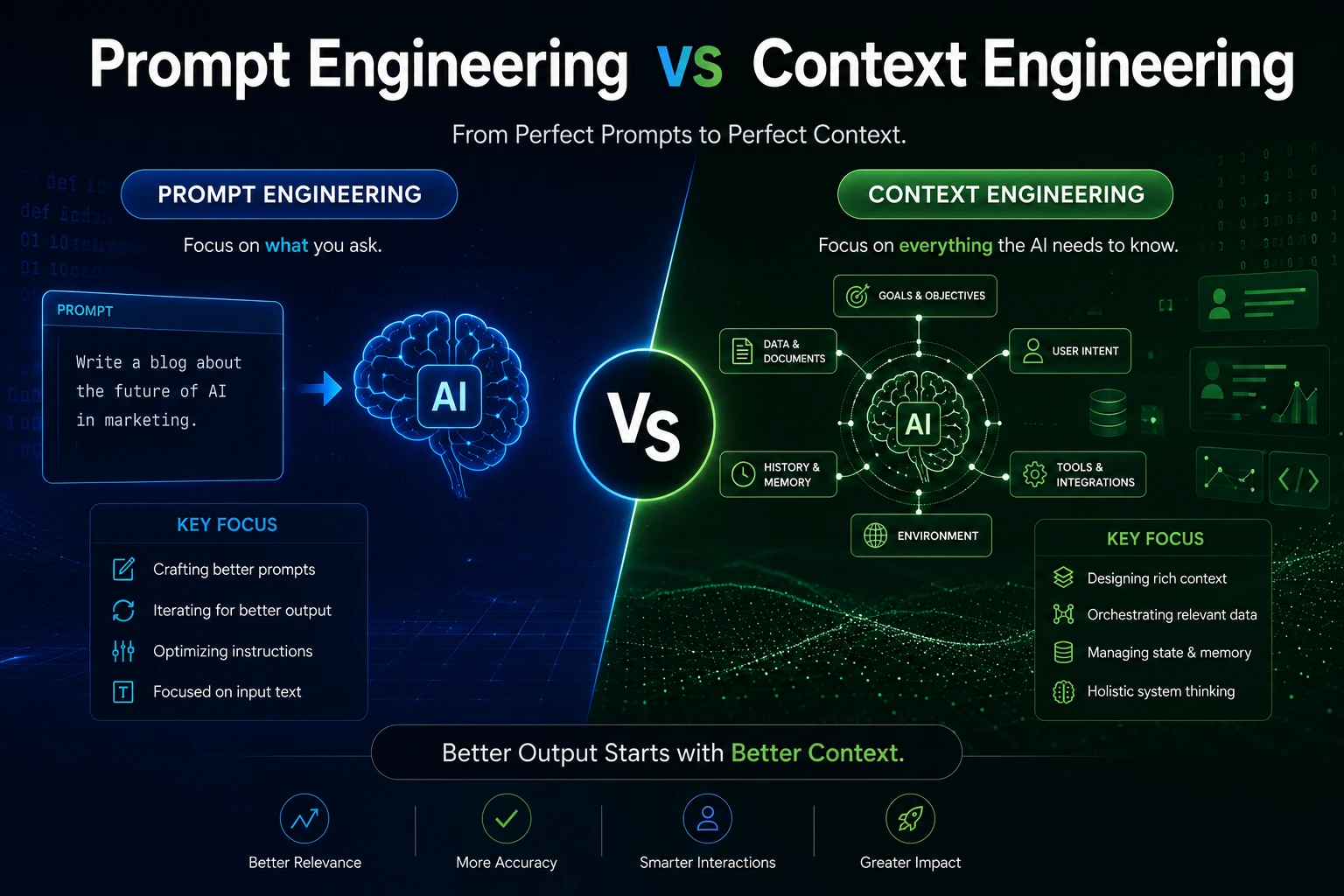
Quick Answer: Context engineering is the practice of designing, managing and delivering the right information to an AI system at the right time. Unlike prompt engineering, which focuses on wording a single input, context engineering includes user history, business rules, documents, APIs, memory, tools, retrieval systems, real-time data and governance. It is essential for reliable AI agents and enterprise AI systems.
Prompt engineering helped people get better answers from early AI models. But modern AI systems are moving beyond single, isolated prompts. Businesses now require AI agents that can utilize proprietary company data, retrieve specific documents, remember user preferences, follow strict corporate policies, securely call tools, and act safely in complex environments.
That massive shift is why context engineering is rapidly becoming more important than prompt engineering alone. The future of AI performance is not just about writing better prompts; it is about building better context infrastructure.
Build Reliable AI Systems With Context Engineering
Intellectual Clouds helps businesses design AI context architecture, RAG pipelines, knowledge bases, AI agents, workflow automation and structured data systems that make enterprise AI more accurate, reliable and useful.
Design Your Context Architecture Today
What Is Prompt Engineering?
Prompt engineering is the art and science of structuring instructions or queries so that a Large Language Model (LLM) understands exactly what you want and returns an optimal response. It involves using specific constraints, tone directives, formatting requests, and few-shot examples within a single text box.
Why Prompt Engineering Became Popular
When ChatGPT first launched, users quickly realized that asking "Write a blog post about AI" yielded generic, boring results. However, asking "Act as a senior AI researcher. Write an engaging, 500-word blog post about AI agents targeting enterprise executives, using a professional but accessible tone. Include a bulleted list of benefits," produced vastly superior outputs.
Prompt engineering became the vital bridge between human intent and machine understanding in the early days of generative AI.
Why Prompt Engineering Alone Is No Longer Enough
The core limitation of prompt engineering is that it relies on the user to manually provide all necessary information in every single interaction.
If you are a customer service agent using AI, you cannot manually paste a customer's entire 3-year purchase history, your company's 50-page return policy, the current inventory database, and the user's recent support tickets into a single prompt every time you ask the AI for a suggested reply.
Prompt engineering is fragile, difficult to scale, and fundamentally inadequate for custom AI agents for Salesforce or other robust enterprise systems that require deep, dynamic, and automated awareness of their environment.
What Is Context Engineering?
If prompt engineering is deciding exactly what to say in a conversation, context engineering is setting the stage, providing the background files, briefing the participants, establishing the rules of engagement, and providing the tools needed before the conversation even begins.
Context engineering is the systematic discipline of designing, managing, and delivering the precise informational environment an AI system needs to operate effectively. It encompasses:
Prompt Engineering vs Context Engineering
While the title "Prompt Engineering is Dead" makes for a catchy headline, the reality is more nuanced. Prompt engineering is not entirely dead; rather, it is becoming just one foundational layer inside the much larger architecture of context engineering.
| Area | Prompt Engineering | Context Engineering |
|---|
| Focus | Better wording | Better information architecture |
| Scope | Single prompt | Full AI system |
| Works Best For | Simple, isolated tasks | Enterprise AI and autonomous agents |
| Data Source | User input | Docs, APIs, memory, databases |
| Reliability | Limited (prone to hallucinations) | Higher with good retrieval and governance |
| Personalization | Basic | Deep user and business context |
| Scalability | Hard to maintain consistently | Designed for repeatable AI workflows |
The AI Context Architecture
To understand how context engineering works in practice, look at the architecture of a modern AI response system. It is no longer a straight line from user to LLM.
User Request
↓
[ Prompt / Intent Parsing ]
↓
[ Memory Context ] (What did we discuss previously?)
↓
[ Retrieval / RAG ] (What do our internal documents say?)
↓
[ Tool/API Context ] (What is the live data from the CRM?)
↓
[ Policy & Governance ] (Are there rules restricting this answer?)
↓
[ LLM Synthesis ]
↓
AI Response
A "Before and After" Example
Before (Prompt Engineering Only):
Generic Prompt: "Write an email to a customer who asked for a refund on their software subscription."
Result: A generic, hallucinated email that might offer a full refund even if your company policy only allows pro-rated refunds.
After (Context Engineering):
User Input: "Write a refund email for customer ID 12345."
System Automatically Adds:
- Customer History: "Customer has been active for 3 years, requested cancellation today."
- Policy Docs: "Standard policy: No full refunds after 30 days. Offer 1 free month or pro-rated refund."
- Real-time CRM Data: "Subscription tier: Enterprise. Last interaction: Complained about bug #992."
Result: A highly personalized, policy-compliant email apologizing for bug #992, acknowledging their 3-year loyalty, and offering a pro-rated refund or a free month to stay.
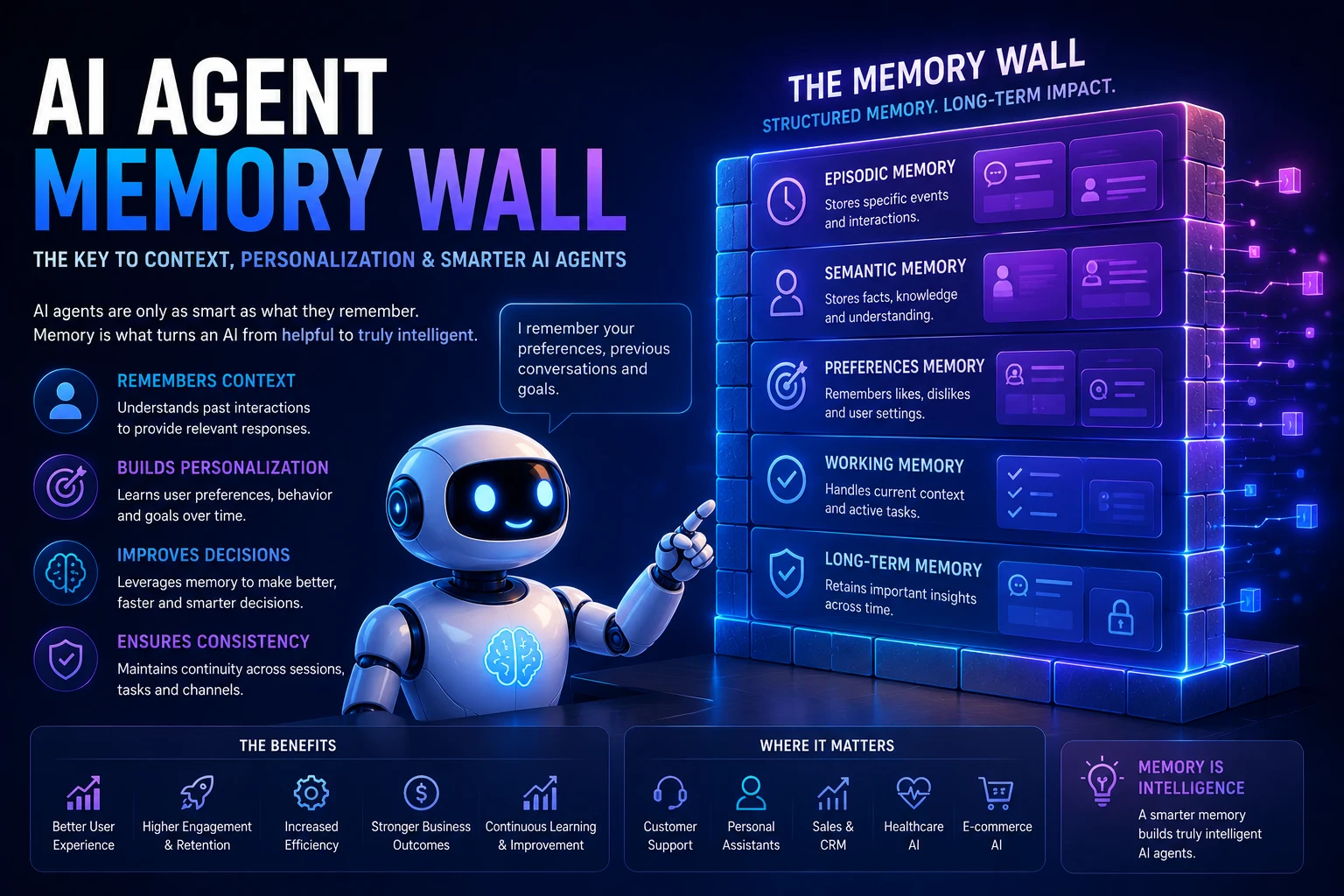
Why AI Agents Need Context
When we talk about overcoming the AI agent memory wall, we are talking about context engineering. AI agents are designed to be autonomous—they reason, plan, use tools, and execute multi-step workflows.
If an AI agent lacks context, it cannot function. It will make incorrect assumptions, misuse tools, or violate company policies.
Research Insight: Anthropic explicitly notes that effective agents rely heavily on robust retrieval, accurate tools, and persistent memory. They warn that deploying agentic systems without proper context frameworks dramatically increases latency, cost, and the risk of catastrophic errors. Context systems require deliberate design, rigorous testing, and strict guardrails.
The Role of RAG in Context Engineering
Retrieval-Augmented Generation (RAG) is the engine room of knowledge context. Instead of relying on the LLM's pre-trained (and potentially outdated) knowledge, RAG dynamically searches a vector database of your company's documents, extracts the relevant pieces, and injects them into the AI's context window.
Research Insight: According to IBM, RAG connects LLMs with external knowledge bases so they generate responses that are far more relevant, current, and domain-specific. While IBM notes RAG lowers hallucination risk, they emphasize it does not make models error-proof on its own—which is why RAG must be wrapped in broader context engineering practices.
The Main Layers of Context Engineering
To build a reliable enterprise AI system, you must engineer multiple layers of context simultaneously.
| Context Layer | Example Elements | Why It Matters |
|---|
| User Context | Role, goals, skill level, preferences | Ensures highly personalized output. |
| Business Context | SOPs, corporate policies, brand voice rules | Guarantees company-aligned, compliant responses. |
| Knowledge Context | Internal docs, product FAQs, manuals via RAG | Provides factual, accurate answers. |
| Task Context | Current project status, active files, chat history | Drives relevant and accurate execution. |
| Tool Context | Available APIs, CRM connections, database access | Enables the agent to take real-world actions. |
| Real-Time Context | Live inventory, market data, open support tickets | Prevents the AI from giving stale or outdated answers. |
| Memory Context | Past interactions, historical decisions | Maintains conversational continuity. |
| Governance Context | Compliance rules, role-based access permissions | Controls risk and prevents data leaks. |
Research Insight: LangChain defines context engineering for agents as the delicate art of filling the context window with the absolute right information at each specific step. They break it down into four main strategies: write, select, compress, and isolate context, ensuring the LLM is neither starved of data nor overwhelmed by noise.
How Context Engineering Reduces Hallucinations
We frequently discuss how AI hallucinations pose a severe brand risk. Context engineering is the antidote.
When an LLM lacks context, it guesses. When it guesses, it hallucinates. By engineering the context pipeline to force the AI to rely only on retrieved documents (Knowledge Context) and live API data (Real-Time Context), you drastically shrink the space in which the AI is allowed to "improvise."
How Businesses Can Build Context Infrastructure
Transitioning from writing ad-hoc prompts to building robust context architecture requires a strategic shift.
- Create a Centralized Knowledge Base: Your AI is only as good as the data it reads. Centralize and create knowledge graphs for AI.
- Clean and Structure Data: Messy SOPs, outdated FAQs, and conflicting policies will confuse the AI. Format your content for AI crawlers and retrieval systems.
- Implement a Robust RAG Pipeline: Set up vector databases that can quickly retrieve the most semantically relevant chunks of data.
- Define Data Permissions and Access Controls: Ensure your context engine respects user roles. A customer service agent's AI should not have context access to HR payroll documents.
- Develop an AI Memory Strategy: Decide what information should be persisted across sessions (e.g., user preferences) and what should be discarded.
- Carefully Design Tool and API Access: Give agents distinct, well-documented APIs to fetch live data (like checking Salesforce or inventory).
- Utilize Context Ranking and Compression: LLM context windows are large, but filling them with irrelevant noise degrades performance. Rank and compress retrieved data before feeding it to the AI.
- Establish an Evaluation System: Continuously test AI outputs against expected baselines.
- Monitor Context Freshness: Ensure the data feeding your RAG pipeline is updated in real-time.
- Add Guardrails: Implement strict rules for what the AI should do if it cannot find the right context (e.g., "I don't know, let me transfer you to a human").
Common Context Engineering Mistakes
Even advanced teams stumble when building context architectures. Avoid these common pitfalls:
- Building a Prompt Library Instead of a Knowledge System: Storing hundreds of prompt templates won't solve systemic data access issues.
- Feeding the AI Outdated Documents: Context is useless if it's stale.
- The "Dump Everything" Approach: Putting every data source into the context window causes the LLM to lose focus ("lost in the middle" syndrome).
- Ignoring Permissions: Failing to implement role-based access control in your RAG pipeline is a massive security risk.
- RAG Without Evaluation: Implementing RAG but never formally testing if the retrieved chunks actually answer the user's query.
- Unclear Tool Descriptions: If the descriptions of the APIs available to the agent are ambiguous, the agent will call the wrong tools.
- Neglecting Agent Memory Testing: Failing to verify if the agent correctly recalls past interactions.
- No Human-in-the-Loop: Allowing high-risk actions (like sending contracts or issuing refunds) without human approval during the transition phase.
- Failing to Cite Sources: Not forcing the AI to output citations showing which piece of context it used to generate its answer.
Context Engineering Implementation Checklist
☐ Clean and structure all vital SOPs and policies
☐ Set up a high-quality Vector Database (RAG)
☐ Map out exact Tool/API access requirements
☐ Define strict Role-Based Access Controls (RBAC)
☐ Implement semantic chunking and ranking
☐ Develop a persistent memory architecture
☐ Create fallback protocols for missing context
☐ Setup output evaluation and hallucination monitoring
☐ Integrate real-time data feeds (e.g., Salesforce, CRM)
☐ Mandate source citations in all AI responses
Frequently Asked Questions
What is context engineering?▼
Context engineering is the systematic design and management of the informational environment an AI operates within, including user history, business rules, documents, APIs, and real-time data.
Is prompt engineering dead?▼
No, but it is becoming just one layer within the broader discipline of context engineering. It is no longer sufficient on its own for complex enterprise AI systems.
What is the difference between prompt engineering and context engineering?▼
Prompt engineering focuses on optimizing a single input query. Context engineering focuses on architecting the entire data and rule environment the AI uses to generate responses across workflows.
Why do AI agents need context?▼
AI agents need context to make autonomous decisions, understand user intent deeply, follow business policies, and use tools correctly without hallucinating.
How does RAG support context engineering?▼
Retrieval-Augmented Generation (RAG) is a core mechanism of context engineering that dynamically fetches relevant documents and data to ground the AI's response in verified facts.
Can context engineering reduce hallucinations?▼
Yes, by providing strict boundaries, factual grounding data, and clear business rules, context engineering significantly reduces the likelihood of AI hallucinations.
What are the main types of AI context?▼
Main types include User Context, Business Context, Knowledge Context, Task Context, Tool Context, Real-Time Context, Memory Context, and Governance Context.
How can businesses build context engineering systems?▼
By centralizing knowledge bases, implementing RAG pipelines, defining access controls, building AI memory strategies, and setting up rigorous evaluation systems.
Is context engineering useful for Salesforce and enterprise AI?▼
Absolutely. It is essential for ensuring AI integrations in platforms like Salesforce operate reliably, securely, and within company guidelines. (See our guide on integrating Salesforce with ChatGPT).
Can Intellectual Clouds help with context engineering?▼
Yes, Intellectual Clouds specializes in designing AI context architecture, RAG pipelines, and reliable enterprise AI agents. We help businesses optimize their websites for ChatGPT and implement AEO strategies alongside robust agentic infrastructure.
Ready to Move Beyond Prompt Engineering?
Intellectual Clouds helps businesses design AI context architecture, RAG pipelines, knowledge bases, AI agents, workflow automation and structured data systems that make enterprise AI more accurate, reliable and useful.
Contact Our AI Architecture Team